
Published 2014-08-12.
Last modified 2019-07-05.
Time to read: 13 minutes.
Scala offers several options for multi-threading. This lecture describes the foundation for Scala’s concurrency and parallelism, and explores how the fork-join framework supports Scala parallel collections and Scala Futures.
This lecture, and most of the other lectures in this section, is updated material originally published in my book Composable Futures with Akka 2.0, which is now obsolete because it was written for Scala 2.9 and Akka 2.0.
Until 2003, computers were able to run faster simply by increasing clock speed. We have since hit the limits of physics and now can only increase the speed of computation by doing many things at once, using multiple threads. Each thread requires significant CPU resources, however.
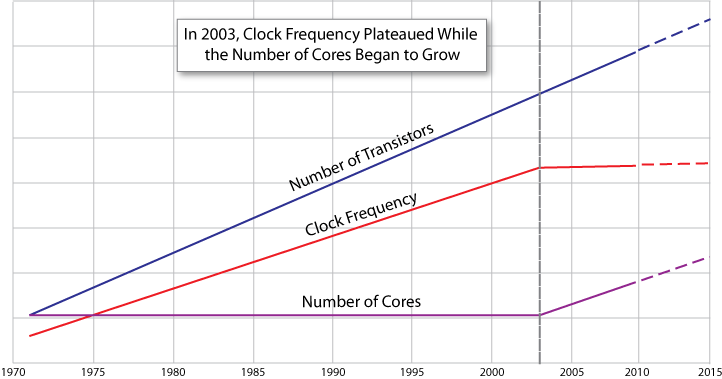
Threads are independent, heap-sharing execution contexts, each with their own stack, scheduled by the operating system. The system manages how these threads are mapped to physical hardware and how they are preempted and interleaved. Thread creation is expensive, so thread pools are used to minimize thread creation. However, managing thread pools introduces additional complexity and programs that use multiple threads are vulnerable to many problems that single-threaded programs do not encounter. Regardless of whether a thread pool is used or not, it is costly to switch contexts when threads are awoken and suspended.
The diagram below, from ITHare.com, shows how expensive a context switch is, when compared to other things that a computer might do. Costs for context switches can be more than two orders of magnitude greater than the next slowest CPU operation (throwing and catching an exception). The ITHare article is based on a paper from Rochester University entitled “Quantifying The Cost of Context Switch”, and written by Chuanpeng Li, Chen Ding, and Kai Shen.

Paraphrasing the ITHare.com article, there are two cost factors in relation to context switches:
- The direct costs of thread context switching, which is measured at about 2000 CPU cycles. You might be interested in reading about how context switches have evolved on Linux.
- Cache invalidation due to thread preemption is the dominant factor. According to the cited paper, the cost of cache invalidation is typically 1M CPU clock cycles, but might range as high as 3M CPU clock cycles.
The actual overhead for the second factor, cache invalidation, varies a lot between CPU models because of varying L1, L2 and L3 cache characteristics and sizes. Thus test results for a specific computer may contradict the results of running the same test on another computer. It is therefor important to run benchmarks on the identical computer as used in production.
Notice the comparison at the bottom of the infographic that shows how far light travels during each CPU operation. This is relevant because electricity travels at less than the speed of light, and in fact electrons must travel the distances shown in order to perform these CPU operations.
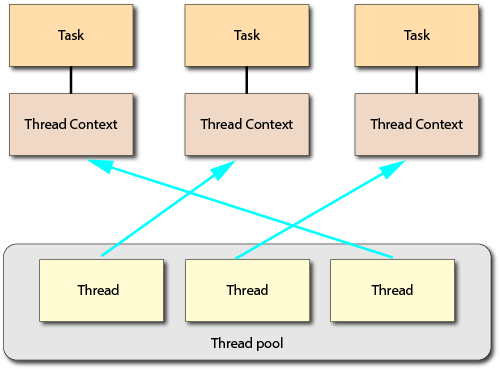
Why go to the trouble of explaining all this? To point out that multithreading is a powerful technique that, when used appropriately, can deliver significant throughput improvements.
However, multithreading is not a panacea and should be used after testing on the production machine(s) demonstrates that it provides that benefit for your specific program.
Here are two more definitions:
Parallelism is the number of threads assigned to a task.
Parallelism factor is the ratio of total assigned threads to busy threads; which means that the other assigned threads are blocked. For example, if 10 threads are assigned to a task, and only two are busy while 8 are blocked, the parallelism factor is 5 (= 10 threads assigned / 2 threads busy). Parallelism factor is an important metric to know when selecting and configuring a thread pool.
Concurrency Definitions
These definitions are not universal, but they are the definitions that I use in this course. These definitions are not the same as those used in the Java documentation, however these are widely accepted in the Scala community.
- Concurrent tasks are stateful, often with complex interactions
- Parallelizable tasks are stateless, do not interact, and are composable
- Multithreading is a generalization of concurrency and parallelization
Callbacks vs. Composition
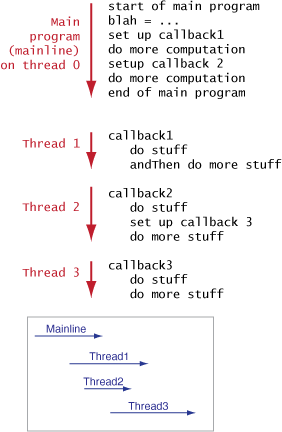
There are two commonly used multithreading techniques: writing in a functional style using composition, and writing callbacks.
Callbacks generally require shared mutable state, however this leads to race conditions which are difficult to debug. Programs exclusively written using callbacks are a jumble of disconnected routines. Writing multithreaded code exclusively in Java requires you to use callbacks. Java has only limited compositional support.
The java.util.concurrent
package supports Java’s multithreading facility and is often abbreviated as j.u.c.
Scala uses the j.u.c. thread support and enhances it so you can write multithreaded code in a functional style without shared mutable state.
Functional-Style Pipelines
Functional composition disallows the use of shared mutable state. You probably have experience with Unix-style pipes, such as provided by Linux and Mac OS is a form of linear composition: a number of processes are chained together, such that the output of each process becomes the input of the next process. The original data is not modified, instead the data passed between processes is private to that exchange and is discarded once consumed. The Combinators lecture earlier in this course introduced this style of programming.
Below we see a file, whose contents are listed with the Linux cat command,
and the output of the cat command is piped into the sort command,
then the sorted output is piped into the uniq command,
then the output of uniq is piped into the input of the tail command,
resulting in another dataset, which is a transformed version of the original dataset.
The original dataset is unchanged.
In fact, each command outputs a temporary dataset which is a transformed version of the data that was inputted to it.

Scala parallel collections and futures, and the Akka library’s multithreading options such as Actors,
all support function-style composition.
Here we see an example of serial / linear data chunked into parallel data sets running on multiple threads,
whereby they are further transformed and then a reduce step that combines the parallel data sets using composition.
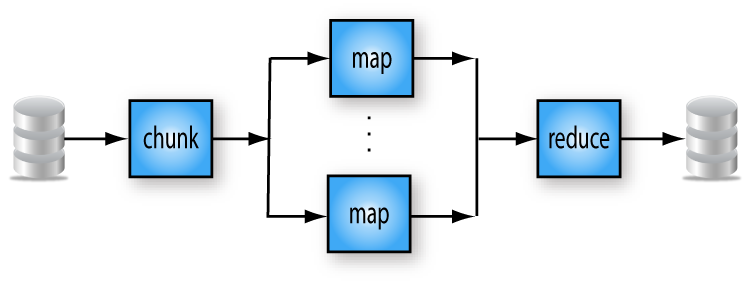
We will talk about how multi-threaded composition works for each type of multithreading in the lectures that follow.
Better MultiThreading Options
Scala programs can take the best of what Java has to offer, and augment it with Scala goodness. The Scala language additionally offers parallel collections; this is only available for Java via a third-party library, Java Stream API Virtual-Threads-enabled Parallel Collectors. You can read about the Java library in Guide to Java Parallel Collectors Library.
The following multithreading options are ordered by increasing complexity and overhead.
-
java.util.concurrent (
j.u.c.) – The foundation of Scala’s multithreading capability is built on this package from the Java runtime library. Efficient and scalable multi-threaded Scala programs can be written at a higher level than Java code that relies onj.u.c. - Scala parallel collections are provided by the Scala runtime library. The Parallel Collections lecture is dedicated to this topic.
- Scala futures are provided by the Scala runtime library. The Futures & Promises lecture is the first of several lectures dedicated to this topic.
You can mix and match the above in the same program.
I published an article in InfoQ entitled Benchmarking JVM Concurrency Options for Java, Scala and Akka, on April 23, 2012. At that time, Akka was still open-source.
Threads
There is a lot to say about j.u.c. threads, and it is important to know about them in order to write and deploy multithreaded Scala code.
I’ve carefully chosen a path through the material that provides a basis to build on in the lectures that follow.
Links are provided so you can learn more.
Daemon Threads
Your Scala or Java program normally executes from beginning to end,
but if it creates additional regular threads your program will not stop when System.exit, or a similar method, is called;
the program will only end when all of those threads have also stopped.
Contrast this behavior with that of daemon threads, which automatically terminate when the main thread exits.
Most ExecutorServices create regular threads, which are not stopped them unless they are explicitly shut down, or they shut themselves down.
If you find that your program will not exit, then either your program must terminate threads it no longer needs, or it should use daemon threads.
Standard Thread Pools
j.u.c. provides a variety of
Executors,
and you can create more.
Executors contain factories and utility methods for concurrent classes such as
ExecutorService and
Callable.
All of the j.u.c. interfaces and classes are important when working with Scala multithreading libraries.
Scala uses Java threadpools exactly like any other Java library would.
One important use of Executors is to create threadpools with various characteristics.
ExecutorServices manage a threadpool and distribute tasks to worker threads.
Proper selection of the type of threadpool that your application requires is important in order to obtain the desired behavior.
The flow chart below is taken from
Jessica Kerr’s
"Choosing an ExecutorService" blog posting,
note that it does not apply to Scala parallel collections because they always use ForkJoinPool, described below.

Java provides several built-in types of threadpools, as described in the table below.
The threads in all these standard pools, except ForkJoinPool, will continue to exist until they are explicitly shut down because they use regular threads.
The Javadoc comment for ExecutorService.shutdown() reads
“Initiates an orderly shutdown in which previously submitted tasks are executed, but no new tasks will be accepted.
Invocation has no additional effect if already shut down.”
The class-level Javadoc goes further and says
“An unused ExecutorService should be shut down to allow reclamation of its resources.”
shutdown can fail, and those failures can be caught with an instance of
RejectedExecutionHandler.
Programs can use more than one threadpool, according to their needs.
| Name | Description |
|---|---|
| fork / join |
java. –
It is suitable for IO-bound and recursive tasks and is the default thread pool for Scala and Akka.
Scala provided its own version of ForkJoinPool until
Scala 2.12, which deprecated
scala.concurrent.forkjoin.ForkJoinPool.
You can see the other type aliases deprecated by Scala 2.12
here.
Fork / join is the most complex of the standard Executors, and incurs slightly more overhead.
Unlike all the other executors, fork/join creates daemon threads.
The fork / join framework is intended to be used with programs that can be recursively broken into smaller pieces. The result is that all the available processing power is efficiently used when running the application. The fork / join framework uses a work-stealing algorithm, which means that when worker threads complete their task, they can steal tasks from the inbound queues of other busy threads. When constructing an instance of the fork/join thread pool, the parallelism parameter is used to create the initial number of threads. As execution continues, ForkJoinPool may increase the number of threads to maintain the desired parallelism.
The j.u.c. version of the fork/join thread pool does not provide an upper limit on the number of threads,
however the Scala version does.
|
| cached |
Executors.newCachedThreadPool – Useful for CPU-intensive tasks with a varying load.
Creates new threads as needed, but will reuse previously constructed threads when they are available.
|
| fixed |
Executors.newFixedThreadPool(n) – Useful for CPU-intensive tasks with a constant load.
Reuses n threads operating off a shared unbounded queue.
If additional tasks are submitted when all threads are active, they will wait in the queue until a thread is available.
If any thread terminates due to a failure during execution prior to shutdown, a new one will take its place if needed to execute subsequent tasks.
|
| scheduled |
Executors.newScheduledThreadPool(corePoolSize, threadFactory) – Can schedule commands to run after a given delay, or to execute periodically.
Not used by Akka, and generally not used with Scala because it is computationally expensive.
If you have a demanding application that needs tasks to run according to precise timing then this is a reasonable option to consider.
|
| single |
Executors.newSingleThreadExecutor – A single worker thread operating off an unbounded queue.
If this single thread terminates due to a failure during execution prior to shutdown, a new one will take its place if needed to execute subsequent tasks.
Tasks are guaranteed to execute sequentially, and no more than one task will be active at any given time.
If you need to manage a resource by pinning a thread to that resource, or to runs tests in a deterministic manner then this is a reasonable option to consider.
|
| single scheduled |
Executors.newSingleThreadScheduledExecutor – A single-threaded executor that can schedule commands to run after a given delay, or to execute periodically.
If this single thread terminates due to a failure during execution prior to shutdown, a new one will take its place if needed to execute subsequent tasks.
Tasks are guaranteed to execute sequentially, and no more than one task will be active at any given time.
Not used by Akka, and generally not used with Scala because it is computationally expensive.
If you need to manage a resource by pinning a thread to that resource, and operating on the resource at precise times then this is a good candidate to consider.
|
MultiThreading Support Classes
The boxes with dark blue background are Java classes; the boxes with the lighter blue background are provided by the Scala runtime library. The boxes with gray backgrounds are provided by Akka.
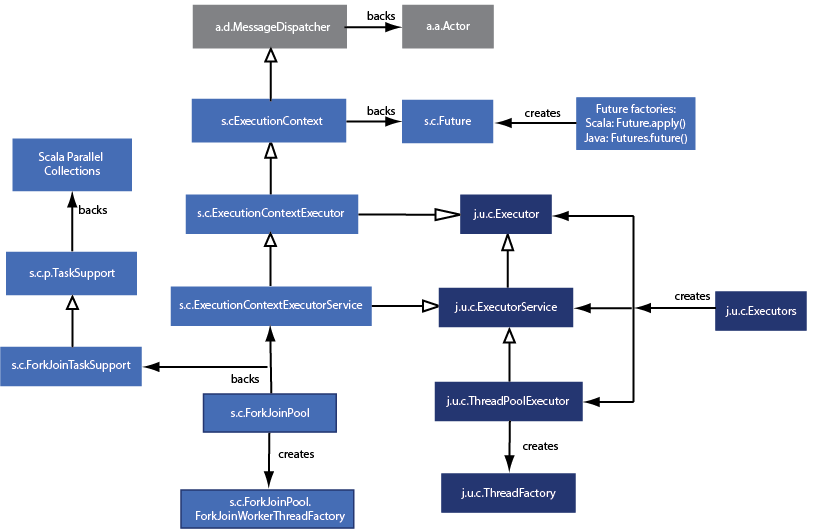
The above diagram is an artistic rendering of the multithreading support classes provided by Java and Scala. Some liberties were taken; not all classes have been shown and only the most important relationships are shown.
Let’s discuss each of these packages and classes. Some of the following descriptions are taken from the Scala and Java documentation.
-
java.util.concurrent(abbreviated asj.u.c.) provides utility classes commonly useful in multithreaded programming used by Java, Scala and Akka.-
Most Scala programmers only need to know about the following classes and interfaces from this package:
Executoris an interface that oversees the submission ofRunnabletasks.-
ExecutorServiceis a concrete implementation of theExecutorinterface, and an instance is required in order to provide threading support for concurrent and parallel functionality. -
ThreadFactorycreates new threads as required.
- Other important classes and interfaces provided by this package:
-
Threads and thread pools, discussed above. -
CompletionService,CountDownLatch,CyclicBarrier,Phaser,Semaphore,TimeUnit– most use cases can benefit from Scala / Akka library features instead of this low-level and error-prone artifacts. Exception:TimeUnitprovides some useful definitions, which both Scala and Akka take advantage of. -
java.util.concurrent.atomic– most use cases can benefit from Scala / Akka library features instead of these low-level classes. If you find your code has race conditions, review your architecture instead of trying to make atomic operations work. A good usage of this package is the creation of new concurrency library routines, such as the interruptibleFuturethat is provided in the Collections of Futures lecture. -
java.util.concurrent.locks– most use cases can benefit from Scala / Akka library features instead of these low-level and error-prone artifacts. If you find your code has race conditions, review your architecture instead of trying to make locks work. - Concurrent collections – already discussed in the Mutable Collections lecture.
- Primitive
Future, not composable, avoid.
-
-
Most Scala programmers only need to know about the following classes and interfaces from this package:
-
scala.concurrent(abbreviated ass.c.) defines primitives for concurrent and parallel programming.-
ExecutionContextexecutes program logic asynchronously, typically but not necessarily on a thread pool. The intent ofExecutionContextis to lexically scope code execution. That is, each method, class, file, package, or application determines how to run its own code. This avoids issues such as running application callbacks on a thread pool belonging to a networking library. The size of a networking library’s thread pool can be safely configured, knowing that only that library’s network operations will be affected. Application callback execution can be configured separately. -
ExecutionContextExecutorService– plumbing, not important.
-
-
scala.collection.parallel(abbreviated ass.c.p.) -
akka.dispatch(abbreviated asa.d.) Manages multithreading for the Akka library.-
MessageDispatcherprovides a threading model for Akka, and can also be used in place of anExecutionContextfor Scala futures. It is useful to be able to target an appropriate parallelism factor at deployment time; the Akka library’s configuration file makes this easy for actors and other concurrency schemes that it supports, including Scala futures. You can control Akka’s multithreading parameters by setting values in aConfigfile, which we discussed in the HOCON Configuration and HOCON Exercise and Extended Example lectures earlier in this course.
-
-
akka.actor(abbreviated asa.a.) Akka library-
Actor– Encapsulates concurrent mutable state.
-
As we shall see over the next few lectures, Scala parallel collections and Scala futures have some similarities,
but as you see from the above, there are significant differences in how internal mechanics of their multithreading works.
On the other hand, the threading support for Scala Futures is quite similar to the threading support for Akka.
In case you were familiar with Scala 2.9 and Akka 2.0, Scala 2.10’s release was coordinated with the Akka 2.1 release.
Futures
were migrated from the Akka 2.0 project to the Scala 2.10 language, and the implementation changed significantly.
Akka 2.0’s ExecutionContext had supported Akka 2.0 Futures, so it also was moved into Scala 2.10.
JVM Command Line Settings
Scala 2.12 dropped support for Java 7 and earlier versions.
Dave Dice at Oracle suggested that if you’re doing large-scale concurrency on Java 7+, you should use
-XX:+,
in addition to other settings such as UseCondCardMark-server, -Xmx and -Xms.
Pavel Khodakovsky wrote up an explanation of UseCondCardMark
and he states that only the Oracle Java HotSpot Server VM supports this option.
Java 8 eliminated permgen from the garbage collection algorithm, so only older JVMs should set
-XX:PermSize and -XX:MaxPermSize.
These options are therefore not useful when working with Scala 2.12+.
Oracle’s documentation states}:
The Generational ZGC is enabled with the command-line options -XX:+UseZGC -XX:+ZGenerational.
The Non-generational ZGC is enabled with the command-line option -XX:+UseZGC.
Garbage Collection Keeps Improving
Java 11 and Java 17 each improved garbage collection. In particular, the new Z garbage collector (QGC) effectively eliminates “stop-the-world” pauses for garbage collection. If your Scala application uses concurrency, you might consider using JDK 17+ and ZGC for your Scala applications.

In Introducing Generational ZGC, Billy Korando explains how Java 21 has improved the Z garbage collector even more. The green line in the following diagram shows the Generational ZGC latency compared to other garbage collectors under heavy load (lowest is best).

This means that for some demanding applications, the generational Z garbage collector introduced with Java 21 can provide a dramatic performance improvement. Generational ZGC will become the default garbage collector when Java 23 is released.
Runtime ExecutionContext Selector
Futures and the Akka library require an ExecutionContext, which is backed by a threadpool.
Scala provides a default implementation, available by importing concurrent..
This executionContext method shows an example of how to use the information presented in this lecture to
select or build an ExecutionContext at runtime.
The sample code for this lecture can be found in
courseNotes/.
/** Returns an instance of the requested type of `ExecutionContext`.
* @args can be `cached`, `fixed`, `forkjoin`, `scheduled`, `single`, `singleScheduled`, `akka*` or the empty String.
* "" is the default, and uses the default global execution context.
* For `akka`, all arguments are used to configure the dispatcher (requires no embedded spaces between arguments), for example:
* <pre>akka.daemonic=on
* akka.actor.default-dispatcher.fork-join-executor.parallelism-min=20
* akka.actor.default-dispatcher.fork-join-executor.parallelism-max=200</pre> */
def executionContext(args: Array[String] = Array.empty[String]): ExecutionContext = {
import java.util.concurrent.{Executors, ExecutorService}
args.toList match {
case a if a.contains("cached") =>
val pool: ExecutorService = Executors.newCachedThreadPool()
ExecutionContext.fromExecutor(pool)
case a if a.contains("fixed") =>
val pool: ExecutorService = Executors.newFixedThreadPool(Runtime.getRuntime.availableProcessors)
ExecutionContext.fromExecutor(pool)
case a if a.contains("forkjoin") =>
val pool: ExecutorService = new concurrent.forkjoin.ForkJoinPool()
ExecutionContext.fromExecutor(pool)
case a if a.contains("scheduled") =>
val pool: ExecutorService = Executors.newScheduledThreadPool(Runtime.getRuntime.availableProcessors)
ExecutionContext.fromExecutor(pool)
case a if a.contains("single") =>
val pool: ExecutorService = Executors.newSingleThreadExecutor()
ExecutionContext.fromExecutor(pool)
case a if a.contains("singleScheduled") =>
val pool: ExecutorService = Executors.newSingleThreadScheduledExecutor()
ExecutionContext.fromExecutor(pool)
case a :: rest if a.contains("akka") =>
val configString = args.mkString("\n")
val config = com.typesafe.config.ConfigFactory.parseString(configString)
val result = akka.actor.ActorSystem("actorSystem", config).dispatcher
result
case a if a.isEmpty =>
/* If you use concurrent.ExecutionContext.Implicits.global, daemon threads are used, so once the program has
* reached the end of the main program any other threads still executing are terminated */
concurrent.ExecutionContext.Implicits.global
}
}
The resulting ExecutionContext should be saved as an implicit value so it is available to any methods
that require an ExecutionContext.
Remember that you can only have one implicit value of a given type within any scope.
Here are some examples of how you could invoke executionContext; .
implicit val ec = executionContext("cached")
implicit val ec = executionContext("fixed")
implicit val ec = executionContext(
"""akka.daemonic=on
akka.actor.default-dispatcher.fork-join-executor.parallelism-min=20
akka.actor.default-dispatcher.fork-join-executor.parallelism-max=200""".stripMargin)
implicit val ec = executionContext()
I encourage you to modify the sample code provided in the remaining lectures of this course by invoking this method to
define various types of ExecutionContext, and see how that affects how the program behaves.
ThreadLocal vs. Fork-Join
This information is not widely known or understood, and accepted practice has changed between 2006 and 2024.
Java’s ThreadLocal
class provides a way for a
Thread
to store data, and is used by many application servers, servlet engines and frameworks such as Google Guice’s custom scopes.
This means that state is associated with specific threads.
Unfortunately, this also means that ThreadLocal is not easily made compatible with thread pools, such as Fork-Join.
ThreadLocal runs counter to functional programming practice because the purpose of ThreadLocal
variables is provide (unofficial) input to a method.
Incorporating dependencies that use ThreadLocal without taking great care in how your code interacts with
those dependencies will lead to issues that are hard to track down, that only appear when deployed to production.
Brian Goetz, Java architect at Oracle, gave a presentation about Java 22 on May 7, 2024 at JAX, where he changed his mind about the following passage in his book on concurrency, first published in 2006:

Thread-local variables are often used to prevent sharing in designs based on mutable singletons or global variables.
For example, a single-threaded application might maintain a global database connection that is initialized at
startup to avoid having to pass a Connection to every method.
Since JDBC connections may not be thread-safe, a multithreaded application that uses a global connection without
additional coordination is not thread-safe either.
By using a ThreadLocal to store the JDBC connection, as in ConnectionHolder in Listing 3.10,
each thread will have its own connection.
ThreadLocal is widely used in implementing application frameworks.
For example, J2EE containers associate a transaction context with an executing thread for the duration of an EJB call.
This is easily implemented using a static ThreadLocal holding the transaction context: when framework
code needs to determine what transaction is currently running, it fetches the transaction context from this ThreadLocal.
This is convenient in that it reduces the need to pass execution context information into every method,
but couples any code that uses this mechanism to the framework.
It is easy to abuse ThreadLocal by treating its thread confinement property as a license to use global
variables or as a means of creating “hidden” method arguments.
Like global variables, thread-local variables can detract from reusability and introduce hidden couplings among classes,
and should therefore be used with care.
Mr. Goetz now has this to say about ThreadLocal and thread pooling:
You need to be very careful about cleaning up any ThreadLocals you get() or set()
by using ThreadLocal’s remove() method.
If you do not clean up when you’re done, any references it holds to classes loaded as part of a deployed webapp
will remain in the permanent heap and will never get garbage collected.
Redeploying/undeploying the webapp will not clean up each Thread’s reference to your webapp’s
class(es) since the Thread is not something owned by your webapp.
Each successive deployment will create a new instance of the class which will never be garbage collected.
You will end up with out of memory exceptions due to java.
space and after some googling will probably just increase -XX:MaxPermSize instead of fixing the bug.
Here is the biggest reason to not use ThreadLocal with Fork-Join:
In A Primer on Scheduling Fork-Join Parallelism with Work Stealing,
Arch Robison states that greedy scheduling can cause a function to return on a different thread that it was called on, causing havoc in codes
that use ThreadLocal storage and possibly breaking some mutex implementations.
It is possible to design a multithreading framework that supports ThreadLocal, and the Future
implementation that Twitter provides in Finagle
does this, and
here is an article that shows some code that does this.
However, the standard Scala Future does not do this, nor does Akka’s Actor implementation,
and Play Framework 2 relies upon standard Scala Futures and Akka.
It is possible to mix ThreadLocal usage with async-style programming using standard Scala multithreading libraries,
but it is difficult to get right, and undocumented changes to libraries can introduce fatal issues that only manifest at runtime.
Beware.
© Copyright 1994-2024 Michael Slinn. All rights reserved.
If you would like to request to use this copyright-protected work in any manner,
please send an email.
This website was made using Jekyll and Mike Slinn’s Jekyll Plugins.