
Published 2014-02-01.
Last modified 2019-07-03.
Time to read: 8 minutes.
Parallel collections are a powerful, yet simple concurrency option built into Scala. Parallel collections should be your first option when considering the type of concurrency mechanism to employ for any given problem.
The sample code for this lecture can be found in
courseNotes/.
Scala parallel collections are written just like regular (serial) Scala collections, but the combinators passed in operate in parallel instead of sequentially. Scala parallel collections are:
- Easy to use
- Minimally configurable
- Blocking
- Composable
- Easy to reason about
They also benefit from ongoing improvements to ForkJoinPool.
There are two types of computations which benefit from multithreading using parallel collections.
- Computationally intensive tasks (CPU bound).
- I/O intensive tasks (I/O bound).
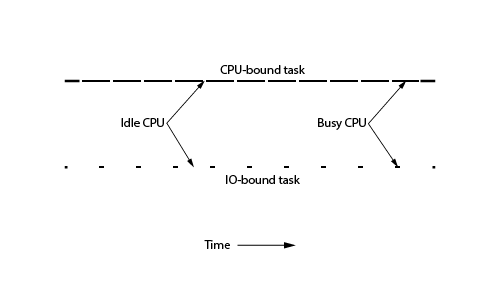
This lecture refers to the functions passed to higher order methods of Scala parallel collections as tasks, because they are actually transformed into Runnable instances so they can be executed in another context, for example on another thread.
Scala parallel collections require idempotent combinators (functions which have no side effects).
Scala 2.13 Changes
Parallel collections were moved into a separate module for Scala 2.13, and that change persists into Scala 3. Library authors should see this issue for cross-building.
Scala 2.13 had been released over a month at the time of updating this lecture, however a complete version of this library was not yet available was not publicly available.
To depend on scala-parallel-collections
in sbt, add the following to build.sbt:.
libraryDependencies += "org.scala-lang.modules" %% "scala-parallel-collections" % "release"
In your Scala source code, adding the following import to each Scala source file that uses parallel collections.
This will enable use of the .par method as in earlier Scala versions.
import scala.collection.parallel.CollectionConverters._
Scaladoc
The parallel collections (ParArray and ParRange, etc.) are not visible in the standard Scaladoc.
- The Parallel Collection Scaladoc for Scala 2.13 is here.
- The Parallel Collection Scaladoc for Scala 3 is is here.
Quick Parallel Demo
Start sbt console from the courseNotes/ directory.
$ sbt console [info] Loading settings for project global-plugins from idea.sbt ... [info] Loading global plugins from /home/mslinn/.sbt/1.0/plugins [info] Loading settings for project coursenotes-build from build.sbt ... [info] Loading project definition from /mnt/c/work/course_scala_intermediate_code/courseNotes/project [info] Loading settings for project coursenotes from build.sbt,eclipse.sbt ... [info] Set current project to intermediate-scala-course (in build file:/mnt/c/work/course_scala_intermediate_code/courseNotes/) [info] Starting scala interpreter... Welcome to Scala 2.13.0 (OpenJDK 64-Bit Server VM, Java 11.0.3). Type in expressions for evaluation. Or try :help.
Now import the collection converters that enable parallel collection, and play with parallel collections:
scala> import scala.collection.parallel.CollectionConverters._ import scala.collection.parallel.CollectionConverters._
scala> Array.empty[Int].par res0: scala.collection.parallel.mutable.ParArray[Int] = ParArray()
scala> (1 to 3).par res1: scala.collection.parallel.immutable.ParRange = ParRange 1 to 3
Transforming a Serial Collection Into a Parallel Collection

To transform a List into a parallel equivalent (ParVector),
simply suffix the collection reference with .par, like this:
scala> List(1, 2,3).par res0: scala.collection.parallel.immutable.ParSeq[Int] = ParVector(1, 2, 3)
All standard Scala collection types, such as Map, have parallelized equivalents:
scala> Map(1 -> "a", 2 -> "b", 3 -> "c").par scala> res1: scala.collection.parallel.immutable.ParMap[Int,String] = ParMap(1 -> a, 2 -> b, 3 -> c)
... and Set:
scala> Set(1,2,3).par scala> res2: scala.collection.parallel.immutable.ParSet[Int] = ParSet(1, 2, 3)
Many more types of Scala parallel collections exist; we shall see them all later in this lecture.
Comparing Execution Speed

Trivial computations can take longer on parallel collections than on Scala collections because there is a cost to assigning work to threads.
This section shows two scenarios where parallel collections can provide significant benefit.
We’ll use the time
higher-order function that was introduced in the
Parametric Types lecture earlier in this course to quantify that benefit.
We will also use the calculatePiFor method that we used earlier in this course as our CPU-bound task.
/** Measure execution time of the given block of code */
def time[T](msg: String)(block: => T): T = {
val t0 = System.nanoTime()
val result: T = block
val elapsedMs = (System.nanoTime() - t0) / 1000000
println(s" Elapsed time for $msg: " + elapsedMs + "ms")
result
}
The following Function1[Int, Double] version of calculatePiFor is provided in
courseNotes/.
val calculatePiFor: Int => Double = (decimals: Int) => {
var acc = 0.0
for (i <- 0 until decimals)
acc += 4.0 * (1 - (i % 2) * 2) / (2 * i + 1)
acc
}
Here is a class for testing CPU bound tasks running on parallel collections:
class CpuBound(val iterations:Int = 10000) {
import collection.parallel.immutable.ParSeq
def goNuts(decimals: Int) = {
println(s"Starting $iterations CPU-bound computations")
time("serial CPU-bound computation") {
(1 to iterations).map(_ => calculatePiFor(decimals))
}
time[ParSeq[Double]]("parallel CPU-bound computation") {
(1 to iterations).par.map { _ => calculatePiFor(decimals) }
}
}
}
val cpuBound = new CpuBound()
val result = cpuBound.goNuts(1000)
Output is:
Starting 10000 CPU-bound computations Elapsed time for serial CPU-bound computation: 134ms Elapsed time for parallel CPU-bound computation: 27ms
Parallel collections executed this CPU-bound task in about 20% of the time taken by serial collections.
We’ll use result a bit later in this lecture, in the Reducing Results section.
Here is a class for testing IO bound tasks running on parallel collections:
class IoBound {
val random = util.Random
val iterations = 10
val fetchCount = 10
/** Minimum time (ms) to sleep per invocation */
val minDelay = 5
/** maximum time (ms) to sleep per invocation */
val maxDelay = 30
val computeRandomDelays = (count: Int) => {
def randomDelay = random.nextInt(maxDelay-minDelay) + minDelay
for (i <- 0 until count) yield randomDelay
}
val randomDelays = computeRandomDelays(fetchCount)
/** Simulate an IO-bound task (web spider) */
val simulateSpider: () => Unit = () => {
for (i <- 0 until fetchCount) {
// Simulate a random amount of latency (milliseconds) varying between minDelay and maxDelay
Thread.sleep(randomDelays(i))
calculatePiFor(50) // Simulate a tiny amount of computation
}
()
}
def goNuts: Unit = {
println(s"Starting $fetchCount IO-bound computations")
time("serial IO-bound computation") {
(1 to iterations).foreach { _ => simulateSpider()}
}
time("parallel IO-bound computation") {
(1 to iterations).par.foreach { _ => simulateSpider() }
}
}
}
new IoBound().goNuts
Output is:
Starting 10 IO-bound computations Elapsed time for serial IO-bound computation: 1782ms Elapsed time for parallel IO-bound computation: 359ms
Parallel collections also executed this IO-bound task in about 20% of the time taken for serial collections.
As you can see, parallel collections are much faster for non-trivial tasks, and code changes necessary to transform a linear map into a parallel map are minimal.
Anti-Demo
Lest you think that Scala parallel collections are always faster than serial collections, here is an example showing how much slower they are for trivial tasks.
class AntiDemo {
def goNuts: Unit = {
println("Quick demo")
time[Long]("sequential sum") { (1L to 10000000L).map(_ * 2L).sum }
time[Long]("parallel sum") { (1L to 10000000L).par.map(_ * 2L).sum }
println()
}
}
new AntiDemo().goNuts
Output is:
AntiDemo Elapsed time for sequential sum: 1343ms Elapsed time for parallel sum: 1448ms
Transforming To and From Parallel Collections
The Parallel Collections ScalaDoc for Scala 2.13 and Scala 3 is:
collection.parallel.mutable:-
ParArray: -
ParHashMap: -
ParHashSet: -
ParTrieMap
-
-
collection.parallel.immutable:-
ParVector: -
ParHashMap -
ParHashSet -
ParRange
-
The parallel versions of the more refined Scala collections are generic, so you lose some of the features present in the serial versions after converting to the parallel version.
You can see this most clearly by converting the parallel collection created by .par back to a serial collection by invoking.seq.
In this section I list each type of serial collection that maps to a given type of parallel collection, and I provide code examples for the round-trip of serial collection to parallel collection and back to a serial collection, which may or may not be of the same type of serial collection that we started with.
Immutable Collections
This section explores how serial collections in collection.immutable round-trip to the equivalent parallel collection in collection.parallel.immutable.
scala> import collection.immutable import collection.immutable
To / From ParMap
The serial collections HashMap, IntMap, ListMap, LongMap,
Map, SortedMap, and TreeMap are all converted to instances of ParMap,
that can be converted back to instances of the Map trait.
scala> immutable.SortedMap(1->"a", 2->"b", 3->"c") scala> res1: scala.collection.immutable.SortedMap[Int,String] = Map(1 -> a, 2 -> b)
scala> immutable.SortedMap(1->"a", 2->"b", 3->"c").par res2: scala.collection.parallel.immutable.ParMap[Int,String] = ParMap(1 -> a, 2 -> b, 3 -> c)
scala> %}immutable.SortedMap(1->"a", 2->"b", 3->"c").par.seq scala> res5: scala.collection.immutable.Map[Int,String] = Map(1 -> a, 2 -> b, 3 -> c)
Notice that the original collection was sorted, so the parallel equivalent maintained the ordering; consider this a coincidence! This behavior is not guaranteed for all collection types.
After converting from ParMap to Map we again see the original order, but this is again a coincidence.
To / From ParRange
The serial collection Range round-trips to ParRange with no loss of fidelity.
scala> (1 to 3) scala> res8: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3)
scala> (1 to 3).par res9: scala.collection.parallel.immutable.ParRange = ParRange(1, 2, 3)
scala> (1 to 3).par.seq res10: scala.collection.immutable.Range = Range(1, 2, 3) %}
To / From ParSet
The serial collections BitSet, ListSet, Set, SortedSet,
and TreeSet are converted to instances of ParSet, that can be converted back to the generic Set trait.
scala> immutable.SortedSet(11, 2, 13, -4) scala> res11: scala.collection.immutable.SortedSet[Int] = TreeSet(-4, 2, 11, 13)
scala> immutable.SortedSet(11, 2, 13, -4).par res12: scala.collection.parallel.immutable.ParSet[Int] = ParSet(-4, 13, 2, 11)
scala> immutable.SortedSet(11, 2, 13, -4).par.seq res13: scala.collection.immutable.Set[Int] = Set(-4, 13, 2, 11)
To / From ParSeq / ParVector
The serial collections IndexedSeq, Iterable, LinearSeq, List,
Seq, Stack, Stream, Traversable, and Vector are
converted to instances of the ParSeq trait, which is implemented by ParVector,
that can be converted back to the generic Seq trait, implemented with Vector.
scala> immutable.IndexedSeq(11, 2, 13, -4) scala> res15: scala.collection.immutable.IndexedSeq[Int] = Vector(11, 2, 13, -4)
scala> immutable.IndexedSeq(11, 2, 13, -4).par res16: scala.collection.parallel.immutable.ParSeq[Int] = ParVector(11, 2, 13, -4)
scala> immutable.IndexedSeq(11, 2, 13, -4).par.seq res17: scala.collection.immutable.Seq[Int] = Vector(11, 2, 13, -4)
Here is another example:
scala> List(11, 2, 13, -4) scala> res22: List[Int] = List(11, 2, 13, -4)
scala> List(11, 2, 13, -4).par res23: scala.collection.parallel.immutable.ParSeq[Int] = ParVector(11, 2, 13, -4)
scala> List(11, 2, 13, -4).par.seq res24: scala.collection.immutable.Seq[Int] = Vector(11, 2, 13, -4)
Mutable Collections
This section explores how serial collections in collection.mutable round-trip to the equivalent parallel collection in
collection.parallel.mutable.
scala> import collection.mutable import collection.mutable
To / From ParArray
The serial collections Array, ArrayBuffer, ArraySeq, ArrayStack,
Buffer, IndexedSeq, Iterable, LinearSeq, ListBuffer,
PriorityQueue, Queue, Seq, Stack, Traversable,
and UnrolledBuffer are converted to instances of ParArray trait,
that can be converted back to ArraySeq.
scala> Array(11, 2, 13, -4) res26: Array[Int] = Array(11, 2, 13, -4)
scala> Array(11, 2, 13, -4).par res27: scala.collection.parallel.mutable.ParArray[Int] = ParArray(11, 2, 13, -4)
scala> Array(11, 2, 13, -4).par.seq res28: scala.collection.mutable.ArraySeq[Int] = ArraySeq(11, 2, 13, -4)
The Scala Collections document
says "Array sequences are mutable sequences of fixed size which store their elements internally in an Array[Object].
They are implemented in Scala by class ArraySeq.
You would typically use an ArraySeq if you want an array for its performance characteristics,
but you also want to create generic instances of the sequence where you do not know the type of the elements."
In other words, ArraySeq achieves extra run-time performance by dispensing with type safety.
To / From ParSet / ParHashSet
The serial collections BitSet, LinkedHashSet, Set, SortedSet,
and TreeSet are converted to instances of ParSet trait, implemented as ParHashSet,
that can be converted back to Set.
scala> mutable.SortedSet(11, 2, 13, -4) scala> res31: scala.collection.mutable.SortedSet[Int] = TreeSet(-4, 2, 11, 13)
scala> mutable.SortedSet(11, 2, 13, -4).par res32: scala.collection.parallel.mutable.ParSet[Int] = ParHashSet(-4, 11, 13, 2)
scala> mutable.SortedSet(11, 2, 13, -4).par.seq res33: scala.collection.mutable.Set[Int] = Set(-4, 11, 13, 2)
To / From ParMap / ParHashMap
The serial collections HashMap, LinkedHashMap, ListMap, LongMap,
Map, OpenHashMap, and WeakHashMap are converted to instances of ParMap trait,
implemented as ParHashMap, that can be converted back to Map.
scala> mutable.WeakHashMap(1->"a", 2->"b", 3->"c") scala> res37: scala.collection.mutable.WeakHashMap[Int,String] = Map(3 -> c, 2 -> b, 1 -> a)
scala> mutable.WeakHashMap(1->"a", 2->"b", 3->"c").par res38: scala.collection.parallel.mutable.ParMap[Int,String] = ParHashMap(2 -> b, 1 -> a, 3 -> c)
scala> mutable.WeakHashMap(1->"a", 2->"b", 3->"c").par.seq res39: scala.collection.mutable.Map[Int,String] = Map(2 -> b, 1 -> a, 3 -> c)
Concurrent Collections
This section explores how serial collections in collection.concurrent round-trip to the equivalent
parallel collection in collection.parallel.mutable.
To / From TrieMap
The serial collection TrieMap round-trips to ParTrieMap with no loss of fidelity.
scala> collection.concurrent.TrieMap(1->"a", 2->"b", 3->"c") res42: scala.collection.concurrent.TrieMap[Int,String] = TrieMap(1 -> a, 2 -> b, 3 -> c)
scala> collection.concurrent.TrieMap(1->"a", 2->"b", 3->"c").par res43: scala.collection.parallel.mutable.ParTrieMap[Int,String] = ParTrieMap(1 -> a, 2 -> b, 3 -> c)
scala> collection.concurrent.TrieMap(1->"a", 2->"b", 3->"c").par.seq res44: scala.collection.concurrent.TrieMap[Int,String] = TrieMap(1 -> a, 2 -> b, 3 -> c)
Other Immutable Parallel Collections
The immutable.ParIterable
()
parallel collection has no transformation via .par.
If you want an instance of it, you must create it explicitly.
scala> collection.parallel.immutable.ParIterable(1, 2, 3) res2: scala.collection.parallel.immutable.ParIterable[Int] = ParVector(1, 2, 3)
Other Mutable Parallel Collections
Several parallel collections have no transformation via .par.
If you want an instance of any of these, you must create them explicitly:
ParIterable: ()ResizableParArrayCombiner: ()UnrolledParArrayCombiner: ()
scala> collection.parallel.mutable.ParIterable(1, 2, 3) res3: scala.collection.parallel.mutable.ParIterable[Int] = ParVector(1, 2, 3)
Tuning Parallel Collections
Scala 2.11 modified and enhanced how parallel collections can be tuned. With Scala 2.11, Java 6+ was required, so older threadpools are not discussed here. This course ignores Scala versions older than 2.12, so enough said about that.
There are currently a few task support implementations available for parallel collections.
ForkJoinTaskSupport uses a
ForkJoinPool
internally and is used by default.
ExecutionContextTaskSupport uses the default execution context
(scala.concurrent.ExecutionContext.Implicits.global),
and it reuses the ForkJoinPool instance provided by scala.concurrent,
so parallel collections by default share the same ForkJoinPool that Scala Future uses.
You can provide another threadpool to parallel collections.
This is useful for I/O bound tasks, where the degree of parallelism needs to be increased due to idle tasks waiting for responses.
By default, ForkJoinPool instances are created with parallelism equal to the number of processors,
which can be discovered by calling
java.lang.Runtime.getRuntime.availableProcessors.
Parallel collections have a tasksupport property which can be queried or set to another thread pool with the desired characteristics.
Here is an example of changing the tasksupport property of a parallel collection to a ForkJoinPool
instance that has parallelism set to 10x the number of CPUs; this would be useful if I/O bound tasks spent 90% of their time idle.
scala> import collection.parallel._ import scala.collection.parallel._
scala> import concurrent.forkjoin.ForkJoinPool import concurrent.forkjoin.ForkJoinPool
scala> val cpus = Runtime.getRuntime.availableProcessors cpus: Int = 8
scala> val parallelism = 10 parallelism: Int = 10
scala> val parArray = Array(1, 2, 3).par pc: scala.collection.parallel.mutable.ParArray[Int] = ParArray(1, 2, 3)
scala> parArray.tasksupport = new ForkJoinTaskSupport(new ForkJoinPool(cpus * parallelism)) pc.tasksupport: scala.collection.parallel.TaskSupport = scala.collection.parallel.ForkJoinTaskSupport@4a5d484a
scala> parArray map { _ + 1 } res0: scala.collection.parallel.mutable.ParArray[Int] = ParArray(2, 3, 4)
Reducing Results
Parallel collections return a collection of values, and it is common to require a reduction step
(the reduce phase of the map/reduce paradigm).
Common reductions include maximum, minimum, average, etc.
Scala collections give you several choices: fold (also known as foldLeft)
and foldRight (also known as foldr).
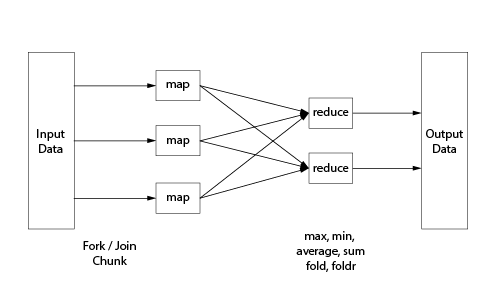
The following example merely counts the number of results that have a “6” in the result,
which we created in the Comparing Execution Speed section above.
First let’s see the results type:
scala> results res3: String = scala.collection.parallel.immutable.ParVector
scala> results.filter(_.toString.contains("6")) res4: String = scala.collection.parallel.immutable.ParVector
Now let’s add up all the values in the collection. This reduction step is also a parallel operation because the collection is parallel.
scala> result.filter(_.toString.contains("6")).reduce { (acc, n) => acc + n } res5: Double = 31405.926538398016
There is a shorter way of writing this:
scala> result.filter(_.toString.contains("6")).sum res7: Double = 31405.926538398016
We could also add a method to ParallelFun to do the reduction.
parSixes uses only two of the available CPU cores, and it uses a for-comprehension to do the counting.
Notice how the yield statement always returns 1 as a Long;
this resulting ParSeq[Long] is stored into result,
and the ParSeq[Long] is reduced by calling result.sum.
def parSixes: Long = {
val result: collection.parallel.ParSeq[Long] = {
import scala.collection.parallel.ForkJoinTaskSupport
val parRange = (1 to iterations).par
parRange.tasksupport = new ForkJoinTaskSupport(new scala.concurrent.forkjoin.ForkJoinPool(2))
for {
i <- parRange
load = calculatePiFor(i) if load.toString.contains("6")
} yield 1L
}
result.sum
}
Now we can invoke parSixes on the cpuBound instance we created earlier:
scala> s"${ cpuBound.parSixes } of the ${ cpuBound.iterations } results had sixes in them." res8: String = 7367 of the 10000 results had sixes in them.
Exercise – Parallel Monkeys
This exercise should take you at least an hour. Please work through it – the exercises for the Future Bad Habits and Exercise lecture features the same problem, and you will be asked to recreate a solution using that multithreading mechanism.
Given a large number of ‘monkeys’,
how many characters of the following text could they match by randomly generating 1000 characters each?
"I thought I saw a lolcat! I did, I did see a lolcat!".
Write a Scala console program that uses Scala parallel collections to run a simulation that generates random characters. The simulation should loop through 10,000 iterations, and compare the result of each iteration with the desired result. Display the longest match.
Hints:
- This is a map/reduce pattern.
-
Here is a method that returns the longest common substring of two strings, starting from the beginning of the string.
FYI, here
is an explanation of what a
viewis, and here is an explanation of whattupleddoes. ThetakeWhilecombinator iterates through a list until it finds one element that doesn’t satisfy the predicate, and returns the elements that did satisfy the predicate. In other words, it returns the longest prefix such that every element satisfies the predicate. If you would like to understand this method better, play with portions of it in the REPL or a Scala worksheet.Scala codedef matchSubstring(str1: String, str2: String): String = str1.view.zip(str2).takeWhile(Function.tupled(_ == _)).map(_._1).mkString
- Here is a method that generates a random string for a restricted alphabet:
Scala code
val random = util.Random
val allowableChars = """ !.,;’""" + ((’a’ to ’z’).toList ::: (’A’ to ’Z’).toList ::: (0 to 9).toList).mkString
def randomString(n: Int) = (1 to n).map { _ => val i = random.nextInt(allowableChars.length-1) allowableChars.substring(i, i+1) }.mkString
Solution
package solutions
object ParMonkeys extends App {
val target = "I thought I saw a lolcat! I did, I did see a lolcat!"
def matchSubstring(str1: String, str2: String): String =
str1.view.zip(str2).takeWhile(Function.tupled(_ == _)).map(_._1).mkString
val random = util.Random
val allowableChars = """ !.,;’""" + ((’a’ to ’z’).toList ::: (’A’ to ’Z’).toList
::: (0 to 9).toList).mkString
def randomString(n: Int) = (1 to n).map { _ =>
val i = random.nextInt(allowableChars.length-1)
allowableChars.substring(i, i+1)
}.mkString
/** return longer of s1 and s2 */
def longestStr (s1:String, s2: String) = if (s1.length>= s2.length) s1 else s2
/** find the longest common substring where the target is matched against each segment of monkeyString */
def simMonkeys (numSims: Int, simStrLen: Int, target: String): String = {
val matchLimit = simStrLen - target.length
/** find the longest common substring where the target is matched against each segment of monkeyString */
def longestCommonSubstring(monkeyString: String): String = {
(0 until matchLimit).par
.map(j => matchSubstring(monkeyString.drop(j), target))
.foldLeft("")(longestStr)
}
(1 to numSims).par
.map(_ => longestCommonSubstring(randomString(simStrLen)))
.foldLeft("")(longestStr)
}
println("Longest common substring: ’" + simMonkeys(50000, 100, target) + "’")
}
You can run the solution I provided in
courseNotes/
this way:
$ sbt "runMain solutions.ParMonkeys"
Lazy Initiation Issues for MultiThreaded Code

When writing multithreaded Scala code,
you might get tripped up by class initialization issues that do not manifest when writing similar single-threaded code.
This type of problem is not specific to Scala parallel collections –
you could encounter it when using Futures, Actors or any other multithreading mechanism.
The sample code for this lecture can be found in
courseNotes/.
scala> object Outer { | val x = 3 | List(0).par.map(_ + Outer.x) | } defined object Outer
scala> Outer.x Hangs... scala> ^C
The above is equivalent to:
object Outer {
val x = 3
List(0).par.map(_ + Outer.this.x)
}
The program hangs because this, the singleton instance of the Outer object,
was referenced from another context (the closure _ + Outer.this.x) before this was fully constructed.
See the Closures lecture of the
Introduction to Scala course to refresh your memory of what a closure is.
This is a result of
how the Java virtual machine initializes classes.
Recall that Scala objects are singleton instances of classes, so this affects them as well.
Oddly enough, the code in the ClassInitProblem.scala file runs fine because it is invoked from a console App primary constructor, and console app initialization is unusual.
The problem manifests in the REPL, and will also manifest in other parts of programs – but not in a console app’s primary constructor.
The recommended solution is to move thread creation outside of the object initializer.
In other words, only create new threads from object methods and Functions.
Here is one way to do that:
scala> class Outer { | val x = 3 | List(0).par.map(_ + Outer.this.x) | } // defined class Outer
scala> new Outer().x res0: Int = 3
You can run the above code by typing:
$ sbt "runMain NoHanging1"
Another solution is to avoid creating closures that reference outer context:
scala> def method(x: Int) = List(0).par.map(_ + x) method: (x: Int)scala.collection.parallel.immutable.ParSeq[Int]
scala> object Outer { | val x = 3 | method(x) | } // defined object Outer
scala> Outer.x res0: Int = 3
You can run this code by typing:
$ sbt "runMain multi.NoHanging2"
SIP-20 - Improved Lazy Vals Initialization
SIP-20 - Improved Lazy Vals Initialization has been proposed to address this issue. When this lecture was recorded (November 2014) this SIP had been implemented several ways and evaluated, but had not been assigned to an upcoming Scala language version. Update June 25, 2019: This SIP is Dormant. Nothing will happen.
© Copyright 1994-2024 Michael Slinn. All rights reserved.
If you would like to request to use this copyright-protected work in any manner,
please send an email.
This website was made using Jekyll and Mike Slinn’s Jekyll Plugins.