
Published 2014-03-10.
Last modified 2019-07-27.
Time to read: 14 minutes.
The sample code for this lecture can be found in
courseNotes/.
The sample code shown in this lecture is provided in collections.CollectionFun.scala.
This lecture introduces the behavior of some common collection types that have both mutable and immutable variants, such as Set,
sequences and Map, and will also discuss Array.
Additional behavior will be discussed in the following lectures.
Not every collection class will be discussed, however those that are not discussed behave according to the rules introduced in the course.
For further information on PagedSeq, UnrolledBuffer and the other neglected collection types, please refer to the Scaladoc
after you have worked through this course material.
PriorityQueue is discussed in the
Sorting and Ordered Collections lecture.
PagedSeq was deprecated for Scala 2.11; for Scala 2.12, PagedSeq was moved out of the Scala runtime library and placed
into the Scala Parser-Combinators project.
Many immutable and mutable collections have the same name, which can be confusing sometimes.
The immutable versions reside in the package
scala.collection.immutable.
The mutable collections reside in the package
scala.collection.mutable.
Prior to Scala 2.13, if the program did not specify, immutable types were assumed, in a vague and rather inconsistent way.
With Scala 2.13 the program must specify either a mutable or immutable type for each referenced collection.
If you don’t then you will either get a rather bland base trait that exhibits limited behavior, or compile error will result that indicates the
method you want (for example, updated)
is not available.
Table of Scala Collection Types
There are mutable versions of most immutable collection types, however the names don’t always suggest that the mutable version is related to the
immutable version.
The table shows special collections (ranges, arrays and LazyList, which will be covered in the
Immutable Collections lecture),
and collection traits and their subclasses along the top.
Foundation traits are mixed in to the other collection traits.
Immutable and mutable variants are shown in separate rows; there is one row of immutable collection traits and classes and three rows of mutable
traits and classes.
In the body of the table, concrete classes are shown in a monospace font and traits are shown in italics.
There are two usable subclasses of mutable collections: linked and concurrent.
Deprecated classestraits
Concurrent collections are inherently threadsafe. They will be discussed in the Mutable Collections lecture.
We will discuss parallel collections (ParArray, ParHashMap, ParHashSet, ParRange,
ParTrieMap and ParVector) in the
Parallel Collections lecture.
This course does not discuss weak hash maps; I believe that Scala’s WeakHashMap does not exhibit useful behavior
and I recommend the
Google Guava weak HashMap instead.
The following table shows the collection types that a Scala programmer is likely to need. As you can see, there are mutable and immutable versions of many types of collections. This lecture and those that follow will explore most of the table rows in detail.
| Collection Traits and Subclasses | |||||||
|---|---|---|---|---|---|---|---|
| Special | Foundation | Set | Sequence | Random Access Sequence | Map | Stack & Queue | |
| Immutable |
OptionParRangeRangeStream
|
IterableParIterableTraversable
|
BitSetHashSetListSetParHashSetParSetSetSortedSetTreeSet
|
ListLinearSeqPagedSeqParSeqSeq
|
IndexedSeqVectorParVector
|
HashMapListMapMapParMapParHashMapSortedMapTreeMap
| Queue
|
| Mutable |
ArrayArrayBufferParArray
|
IterableParIterableTraversable
|
BitSetHashSetListSetParHashSetParSetSetSortedSetTreeSet
|
ArraySeqBufferLinearSeqParSeqSeq
|
IndexedSeqIndexedSeqViewListBuffer
|
HashMapListMapOpenHashMapParHashMapParMapWeakHashMap
|
ArrayStackPriorityQueueStackQueue
|
| Linked |
LinkedHashSet
|
UnrolledBuffer
|
LinkedHashMap
| ||||
| Concurrent | TrieMap
| ||||||
IterableOnce and IterableOps
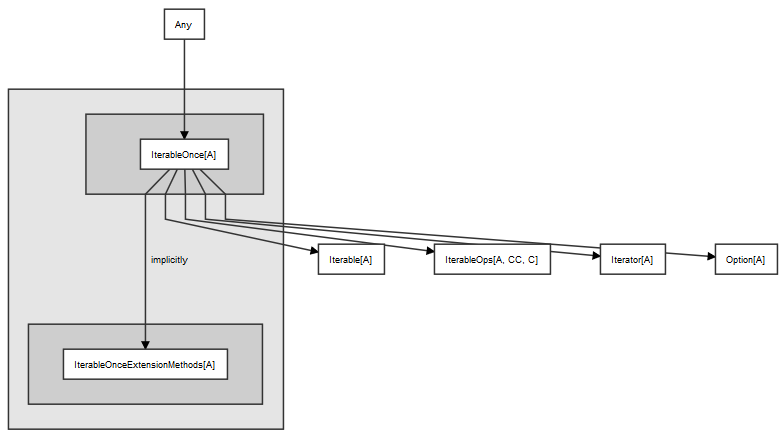
I did not want to talk about
IterableOnce,
but this implementation detail leaks all over the Scala collection API.
This trait is poorly named.
The name suggests (to me) that this trait might limit the number of loops to one, but this is not true.
Instead, this trait is intended for all collections of any size, not just Option.
Perhaps a better name for this trait might be CollectionOps.
IterableOps
comes along for the ride when IterableOnce is mixed into a collection.
Many of the classic functional programming methods are defined in IterableOps.
This trait defines higher order functions such as foreach, map, flatMap, filter,
exists and forall.
We have already seen some of these in action, and we will cover all of them and more in this lecture and lectures that follow.
If your goal is to master functional programming using Scala, I suggest you study both traits and explore the other traits they are associated with.
Set some time aside to do this, because I counted 171 methods in the IterableOps trait alone.
Facility with these methods is essential to becoming an excellent Scala functional programmer.
All of the collections shown in the UML diagrams below implement IterableOnce.
I don’t explicitly show IterableOnce in the UML diagrams - just know it is mixed into almost every class in those diagrams.
Iterable
The Scala collections hierarchy was mercifully simplified with Scala 2.13 and Traversable is no more.
The Iterable
trait now provides the functionality that Traversable used to provide,
and it does so because it mixes in IterableOnceOps.
All collections can be iterated over because they mix in Iterable.
Unless you define your own collection types you won’t define subclasses of Iterable.
Iterator
Iterator
extends IterableOnce and allows iteration over the elements of a collection.
The order of iteration is not defined.
Although Scala’s Iterator is similar to Java’s
Iterator
in that it provides the hasNext and next methods,
you do not normally need to invoke those methods because the IterableOnce trait provide nicer ways to walk through Iterator instances.
Iterators can only be used once, so you might want to get in the habit of transforming an Iterator to a
Vector or a List by calling toVector or toList
if you think might ever need to traverse it again.
For example, we have already seen how we can obtain an Iterator of all of the characters in a source file like this.
scala> val iterator = io.Source.fromFile("build.sbt") iterator: scala.io.BufferedSource = non-empty iterator
You can call
Iterator.mkString,
which invokes toString on each item in the collection, then concatenates the results.
scala> iterator.mkString res0: String = "organization := "com.micronautics" name := "intermediate-scala-course" description := "Core Scala - Intermediate Scala Course Notes"
//scalaVersion := "2.12.8" scalaVersion := "2.13.0"
version := scalaVersion.value
autoCompilerPlugins := true scalacOptions in (Compile, doc) ++= baseDirectory.map { _: File => Seq[String]( "-deprecation", "-doc-source-url", "https://bitbucket.org/mslinn/course_scala_intermediate_code/src/master/coursenotes€{FILE_PATH}.scala", "-encoding", "UTF-8", "-feature", "-target:jvm-1.8", "-unchecked", "-Ywarn-adapted-args", "-Ywarn-dead-code", "-Ywarn-numeric-widen", "-Ywarn-unused", "-Ywarn-value-discard", "-Xlint" ) }.value scalacOptions in Test ++= Seq("-Yrangepos")
javacOptions ++= Seq( "...
Look what happens when I use iterator a second time:
scala> iterator.mkString res1: String = ""
That is horrible behavior ... not even an error message results!
Yes, it is more efficient to deal with raw iterators, but using them introduces a virtual certainty of silent errors that will manifest at runtime.
I suggest that you never use Iterator as a result type and never make a variable with type Iterator, instead,
return any Iterator subclass, such as List, Buffer, etc.
For example, if you wanted to store the collection, you might save it as an immutable.List by calling toList.
The To Converters
lecture will discuss toList and related conversion methods.
scala> val charList = io.Source.fromFile("build.sbt").toList charList: List[Char] = List(o, r, g, a, n, i, z, a, t, i, o, n, , :, =, , ", c, o, m, ., m, i, c, r, o, n, a, u, t, i, c, s, ", , n, a, m, e, , :, =, , ", i, n, t, e, r, m, e, d, i, a, t, e, -, s, c, a, l, a, -, c, o, u, r, s, e, ", , d, e, s, c, r, i, p, t, i, o, n, , :, =, , ", C, o, r, e, , S, c, a, l, a, , -, , I, n, t, e, r, m, e, d, i, a, t, e, , S, c, a, l, a, , C, o, u, r, s, e, , N, o, t, e, s, ", , , /, /, s, c, a, l, a, V, e, r, s, i, o, n, , :, =, , ", 2, ., 1, 2, ., 8, ", , s, c, a, l, a, V, e, r, s, i, o, n, , :, =, , ", 2, ., 1, 3, ., 0, ", , , v, e, r, s, i, o, n, , :, =, , s, c, a, l, a, V, e, r, s, i, o, n, ., v, a, l, u, e, , , a, u, t, o, C, o, m, p, i, l, e, r, P, l, u, g, i, n, s, , :, =, , t, r, u, e, , s, c, a, l, a, c, O, p, t, i, o, n, s, ,...)
We can use the BufferedSource.getLines
method to return an iterator of lines from the file instead of an iterator of characters.
scala> io.Source.fromFile("build.sbt").getLines res2: Iterator[String] = <iterator>
Because there are lots of lines in the file, let’s only report the lines containing the word "Scala".
We can use a filter for this purpose.
The Combinators lecture will discuss filters.
This expression is getting long, and will get longer, so I’ve split it across multiple lines.
The Scala REPL will understand this if a dot is used as a continuation character at the end of each line.
scala> io.Source.fromFile("build.sbt"). getLines. filter(_.contains("Scala")) res3: Iterator[String] = <iterator>
Now it we are ready to transform the collection of lines into a single String.
This optional argument to mkString
specifies that each of the lines in the original collection is to be separated from the next by a comma and a space.
scala> io.Source.fromFile("build.sbt"). getLines. filter(_.contains("Scala")). mkString(", ") res4: String = description := "Core Scala - Intermediate Scala Course Notes", "junit" % "junit" % "4.12" % Test
Now lets use a Java regular expression to replace each occurrence of multiple spaces with only one space.
See the Javadoc for the String.replaceAll method if you are unfamiliar with it.
scala> io.Source.fromFile("build.sbt"). scala> getLines. filter(_.contains("Scala")). mkString(", "). replaceAll(" +", " ") res5: String = description := "Core Scala - Intermediate Scala Course Notes", "junit" % "junit" % "4.12" % Test
You can also invoke
mkString with a prefix and a suffix,
which in this case helps us set off the output from whatever else might be output.
scala> io.Source.fromFile("build.sbt"). getLines. filter(_.contains("Scala")). mkString(">>>\n\t", "\n\t", "\n<<<"). replaceAll(" +", " ") res6: String = >>> description := "Core Scala - Intermediate Scala Course Notes" "junit" % "junit" % "4.12" % Test <<<
A Fine Point
Some students have found this information insightful, others don’t care.
Scala collection classes employ Iterators via
composition instead of inheritance –
in other words, Scala collection classes have Iterators as components and are not Iterator subclasses.
You can see this for yourself by noticing that the
IterableOnce
trait has an abstract method called
iterator,
which is defined like this:
abstract def iterator: Iterator[A]
IterableOnce subclasses implement iterator as a val.
This is an example of using the Uniform Access Principle, discussed in the
Setters, Getters and the Uniform Access Principle lecture of the
Introduction to Scala course, which is a prerequisite for this course.
UML Diagrams of Scala 2.13 Collection Classes
I have created the updates for the last two major releases of
scala-collections-classes,
originally created by by Mathias Doenitz, who goes by the handle
sirthias.
This project generates UML diagrams of the Scala collections classes hierarchy.

Package scala.collection
The scala.collection package contains abstractions common to mutable and immutable collections.
These abstractions (interfaces, abstract traits and abstract classes) do not provide all of the functionality of the mutable and immutable subclasses.
As I’ve mentioned, Scala 2.13 removed some functionality from this package.

Package scala.collection.immutable
This diagram shows Scala’s immutable traits and concrete classes:

Package scala.collection.mutable
This diagram shows Scala’s mutable traits and concrete classes.

Flow Chart for Deciding Which Collection Type to Use
This flow chart, created by Aleksandar Prokopec in response to a Stack Overflow question, can be useful when deciding which collection type to use:

Collection Types
Collections may be strict or lazy.
Lazy collections have elements that do not consume memory or require computation until they are accessed, such as
Ranges,
introduced in the
Learning Scala Using The REPL 2/3 of the preceding Scala Introduction course, and
LazyLists, discussed in
the next lecture.
Collection traits such as Seq, Map and Set define common behavior for concrete implementations.
Both the mutable and immutable collection packages
(scala.collection.mutable and
scala.collection.immutable)
have implementations of collection traits.
You can profitably spend a lot of time studying the collection classes defined in those packages.
You must specify whether you want a mutable or an immutable version when working with a collection type.
If your program just uses immutable data structures, then put this at the top of every .scala file that references
collections.
import scala.collection.immutable._
Similarly, if your program just use mutable data structures,
put the following at the top of every .scala file that references collections:
import scala.collection.mutable._
It is common to use both mutable and immutable data structures in the same program. For this scenario, use the following import and qualify the collection type you need. This course generally adopts that writing style.
import scala.collection._
val x = mutable.Set(1, 2, 3)
val y = immutable.Set(1, 2, 3)
After this overview of collections, we will discuss Immutable Collections, followed by a lecture on Mutable Collections. Many of the capabilities of immutable collections are also implemented by mutable collections. I will point this out in the upcoming lectures. We will then discuss Arrays and Array-Adjacent Types.
Type Widening
Collection items are subject to type widening.
If you put an Int and a Double into a collection, the Ints will be converted to
Doubles and you will get a collection of Double.
scala> immutable.HashSet(1.0, 2) res0: scala.collection.immutable.HashSet[Double] = HashSet(1.0, 2.0)
You can allow collections of Ints and Doubles without type widening by explicitly specifying a collection of
Number.
There are several ways you can express your desires.
One way is to declare the type on the left hand side of the equals sign.
scala> val set: immutable.HashSet[Number] = immutable.HashSet(1.0, 2) set: scala.collection.Set[Number] = Set(1.0, 2)
Specifying a base trait, in this case immutable.Set, also works.
scala> val set: immutable.Set[Number] = immutable.HashSet(1.0, 2) set: scala.collection.Set[Number] = Set(1.0, 2)
It is uncommon to declare a variable to be an instance of a trait, however it is very common to specify a parameter to a method or the return type of a method to be a trait instead of a concrete class. In this example I use both varargs syntax and the placeholder splat syntax introduced in the Classes Part 2 lecture of the Introduction to Scala course.
scala> import scala.collection.immutable import scala.collection.immutable
scala> def newCollection(values: Number*): immutable.Set[Number] = immutable.Set[Number](values: _*) newCollection: (values: Number*)scala.collection.immutable.Set[Number]
scala> newCollection(1.0, 2) res0: scala.collection.immutable.Set[Number] = Set(1.0, 2)
... or you can specify the type of the item contained in the collection on the right hand side of the equals sign:
scala> val set = immutable.HashSet[Number](1.0, 2) set: scala.collection.immutable.HashSet[Number] = HashSet(1.0, 2)
Benchmark and Performance
The online Scala documentation for collections has some out-of-date and incomplete information regarding performance characteristics, written for Scala 2.8, when the Scala Collection Classes were first released. Li Haoyi’s Benchmarking Scala Collections is the best source of information on this topic that I have found, but it was written for Scala 2.11. The Scala collection classes were rewritten for Scala 2.13, so those benchmarks now have limited value. I updated and expanded Li Haoyi’s benchmark program for Scala 2.13, but as of July 22, 2019 I had not yet tabulated the results, which I expect will be very different.
Here are Li Haoyi’s now out-of-date conclusions for the performance of the Scala 2.8 - 2.12 collection classes. Some these conclusions are undoubtedly correct for Scala 2.13, but until the results of an updated benchmark are tabulated it is difficult to know which of these results are no longer accurate, and it there might be more to say.
Arrays are great.
An un-boxed
Arrays of primitives take 1/4th to 1/5th as much memory as their boxed counterparts, e.g.Array[Int]vsArray[java.lang.Integer]. This is a non-trivial cost; if you’re dealing with large amounts of primitive data, keeping them in un-boxedArrays will save you tons of memory.Apart from primitive
Arrays, even boxedArrays of objects still have some surprisingly nice performance characteristics. Concatenating twoArrays is faster than concatenating any other data-structure, even immutableLists andVectors which are Persistent Data Structure and supposed to have clever structural sharing to reduce the need to copy-everything. This holds even for with a million elements, and is a 10x improvement that’s definitely non-trivial. There’s an open issue SI-4442 for someone to fix this, but for now this is the state of the world.Indexing into the
Array, and iterating over it with awhile-loop, are also so fast that the time taken is not measurable given these benchmarks. Even using:+to build anArrayfrom individual elements, ostensibly "O(n^2)" and "slow", turns out to be faster than building aVectorfor collections of up to ~64 elements.It is surprising to me how much faster
Arrayconcatenation is than everything else, even "fancy" Persistent Data Structures likeListandVectorwith structural sharing to avoid copying the whole thing; it turns out copying the whole thing is actually faster than trying to combine the fancy persistent data structures! Thus, even if you have an immutable collection you a passing around, and sometimes splitting into pieces or concatenating with other similarly-sized collections, it is actually faster to use anArray(perhaps boxed in aWrappedArrayif you want it to be immutable) as long as you avoid the pathological build-up-element-by-element use case.Sets and Maps are slow.
Looking up things in an immutable
Vectortakes 1/10th to 1/20th the time looking things up in an immutableSet, and 1/10th to 1/40th the time to look things up in an immutableSet. Even if you convert them to mutable data-structures for speed, there’s still a large potential speedup if you can use aVectorinstead. Using a rawArraywould be even faster.It makes sense, since a
SetorMaplookup involves tons of hashing and equality checks, and even for simple keys likenew Object(which has identity-based hashes and identify-equality) this ends up being a significant cost. In comparison, looking up aVectoris just a bit of integer math, and looking anArrayis a single pointer-addition and memory-dereference.It’s not just looking things up that’s slow: constructing them item-by-item is slow, removing things item-by-item is slow, concatenating them is slow. Even operations which should not need to perform hashing/equality at all, like iteration, is 10 times slower than iterating over a
Vector.Thus, while it makes sense to use
Sets to represent collections which cannot have duplicates, andMaps to hold key-value pairings, keep in mind that they’re likely sources of slowness. If your set of keys is relatively small, and performance is an issue, you could assign integer IDs to each key and replaceSets withVector[Boolean]s andMaps withVector[T]s, looking them up by integer ID. Sometimes, even if you know the collection’s items are all unique, it may be worth giving up the automatic-enforcement that aSetgives you in order to get the raw performance of anArrayorVectororList.Mutable
Sets andMaps are faster and smaller: they take up 1/2 the memory, have 2-4x faster lookups, 2x fasterforeachs, and are 2x faster to construct element-by-element using.addor.put. Even so, working with them is still a lot slower than working withArrays orVectors orLists.Lists vs Vectors.
It’s often a bit ambiguous whether you should use a singly-linked
Listor a tree-shapedVectoras the immutable collection of choice in your code. The whole thing about "effectively constant time" operations does nothing to resolve the ambiguity. However, given the numbers, we can make a better judgment.
Lists have twice as much memory overhead asVectors, the latter of which are comparable with rawArrays in overhead.Constructing a
Listitem-by-item is 5-15x (!) faster than constructing aVectoritem-by-item.De-constructing a
Listitem-by-item using.tailis 50-60x (!) faster than de-constructing aVectoritem-by-item using.tail.Looking things up by index in a
Vectorworks; looking things up by index in aListis O(n), and expensive for non-trivial lists.Iteration is about the same speed on both.
If you find yourself creating and de-constructing a collection bit by bit, and iterating over it once in a while, using a
Listis best. However, if you want to look up things by index, using aVectoris necessary. Using aVectorand using:+to add items or.tailto remove items won’t kill you, but it’s an order of magnitude slower than the equivalent operations on aList.Lists vs mutable.Buffer.
Apart from being an immutable collection,
Lists are often used asvars to act as a mutable bucket to put things.mutable.Bufferserves the same purpose. Which one should you use?It turns out, using a
Listis actually substantially faster than using amutable.Bufferif you are accumulating a collection item-by-item: 2-3x for smaller collections, 1.5-2x for larger collections. A non-trivial difference.Apart from performance, there are other differences between them as well.
mutable.Bufferallows fast indexed lookup, whileListdoesn’.Listis persistent, so you can add/remove things from your copy of aListwithout affecting other people holding references to it.mutable.Bufferisn’t, so anyone who mutates it will affect anyone else using the same buffe.Listis constructed "backwards": the last thing added is first in the iteration order. This might not be what you want, and you may find yourself needing to reverse aListbefore using it.mutable.Bufferon the other hand is constructed "forward", first thing added is first thing iterated ove.mutable.Bufferhas about half the memory overhead of aList.For accumulating elements one at a time,
Lists are faster, and end up having more memory overhead. But if one of these other factors matters to you, that factor may end up deciding on your behalf whether to use aListor amutable.Buffer.Vectors are... ok.
Although
Vectoris often thought of as a good "general purpose" data structure, it turns out they’re not that great.
- Small
Vectors, containing just a single item, have 1/5 of a kilobyte of overhead. While for largerVectors the overhead is negligible, if you have lots of small collections, this could be a big source of wasted memory.Vectoritem-by-item construction is 5-15x slower thanListormutable.Bufferconstruction, and even 40x slower than pre-allocating anArrayin the cases where that’s possible.Vectorindexed lookup is acceptable, but much slower thanArrayormutable.Bufferlookup (though we didn’t manage to measure how much, since those are too fast for these benchmarks.Vectorconcatenation of roughly equal sized inputs, while twice as fast asListconcatenation, is 10x slower than concatenatingArrays: this is despite theArrays needing a full copy whileVectors have some degree of structural sharin.Overall, they are an "acceptable" general purpose collection.
- On one hand, you don’t see any pathological behavior, like indexed lookup in
Lists or item-by-item construction ofArrays: most of theVectorbenchmarks are relatively middle-of-the-pack. That means you can use them to do more or less whatever and be sure you performance won’t blow up unexpectedly with O(n^2) behavior.- On the other hand, many common operations are an order of magnitude slower than the "ideal" data structure: incremental building
Vectors is 5-15x slower than forLists, indexed-lookup is much slower than forArrays, even concatenation of similarly-sizedVectors is 10x slower than concatenatingArrays.
Vectors are a useful "default" data structure to reach for, but if it’s at all possible, working directly withLists orArrays ormutable.Buffers might have an order-of-magnitude less performance overhead. This might not matter, but it very well might be worth it in places where performance matters. A 10x performance difference is a lot.Conclusion.
For example, it’s surprising to me how removing an element from a
Vectoris so much slower than appending one. It’s surprising to me how much slowerSetandMapoperations are when compared toVectors orLists, even simple things like iteration which aren’t affected by the hashing/equality-checks that slow down other operations. It’s surprising to me how fast concatenating largeArrays is, especially compared to things likeVectors andLists which are supposed to use structural sharing to reduce the work required.
Scala 2.13 Breaking Changes
Please see this document.
scala-collection-contrib
scala-collection-contrib
is an open source Scala project and so far has no sponsor.
Volunteer efforts generally do not have the same level of quality that funded projects enjoy.
This project seems to compete with Google Guava’s collection package. Instead of enriching the Google Guava collections (written for Java), this is a reimplementation in Scala. Seems to me like busy work.
From the README:
This module provides various additions to the Scala 2.13 standard collections.
If you’re using sbt, you can add the dependency as follows.
buld.sbtlibraryDependencies += "org.scala-lang.modules" %% "scala-collection-contrib" % "0.1.0"New collection types
MultiSet(both mutable and immutable)SortedMultiSet(both mutable and immutable)MultiDict(both mutable and immutable)SortedMultiDict(both mutable and immutable)New operations
The new operations are provided via a implicit enrichment. You need to add the following import to make them available.
Scala codeimport scala.collection.decorators._The following operations are provided:
Seq
interspersereplacedMap
zipByKey/join/zipByKeyWithmergeByKey/fullOuterJoin/mergeByKeyWith/leftOuterJoin/rightOuterJoin
© Copyright 1994-2024 Michael Slinn. All rights reserved.
If you would like to request to use this copyright-protected work in any manner,
please send an email.
This website was made using Jekyll and Mike Slinn’s Jekyll Plugins.